
사이킷런 찍먹시리즈(4) - 중고차 가격예측
서론
본 글은 작성자의 공부를 위해 쓰는 게시물입니다.
아래 작성하는 글은 틀린내용이 있을수도 있으니 참고하시기 바라며, 책은 핸즈온 머신러닝 2판을 사용하여 공부하고 있습니다.
중고차 가격
이번에는 캐글에 있는 데이터셋인
Used Cars Price Prediction - predict the price of an unknown car. Build your own Algo for cars 을 사용하여
여러가지 데이터 특성을 학습시켜 중고차 가격을 예측하는 모델을 만들어 볼 것이다.
데이터셋은 위의 데이터를 사용한다.
먼저 대략적인 데이터의 특성을 알아보아야 한다.
중고차 가격인 Price가 우리가 예측해야할 타겟이고, 특성의 이름만 봤을 때 가격과 어떤 연관성이 있을지 간단하게 가설을 세워보도록 하자.
- Name : 차종의 이름
차종이름과 회사가 담겨있으므로, 회사의 이름과 차종이 가격과 관련이 있도록 처리해주면, 의미있는 데이터가 될 수도 있을 것 같다. 차종까지 포함하기엔 차종의 종류가 너무 많으니 회사이름만 남기는게 좋을 것 같다.
- Location : 차가 등록된 지역
지역에 따라 존재하는 소득격차가 있으니 아무래도 좋은 지역일수록 좋은차를 타서 가격이 비싼 경향이 있을 것 같다.
지역에 따른 차 가격의 평균을 내보는 방법도 좋겠다.
- Year : 연식
연식이 최근인 차일 수록 가격이 높을 것이다.
- Kilometers_Driven : 주행한 거리
주행한 거리가 적을수록 가격이 높을 것이다.
- Fuel_Type : 사용연료
아무래도 Petrol 보다는 Diesel이 가격이 높은 경향이 있을 것이다.
- Transmissoin : 변속기
변속기 종류가 가격과 관련이 있을까? 검색해보니 동일 차종일경우 스틱이 오토보다 조금 저렴하다고 한다.
- Owner_Type
정확한 설명이 없는데, First, second, third등으로 보아 판매자의 몇번째 차인지를 나타내는 지표같다.
- Mileage
연비, 저가 차량들은 연비가 좋을 수록 가격이 비쌀 수 있겠지만 승차감에 치중한 고급 차종들은 연비가 낮다.
- Engine
배기량, 배기량은 고급차종일수록 높으므로 배기량이 높을수록 비쌀것이다.
- Power
마력, 마찬가지로 마력이 높을 수록 가격이 높을 것이다.
- Seats
좌석의 개수, 좌석의 개수만으로 가격을 판별하기엔 조금 애매할 것 같다.
같은 포지션내에서는 좌석이 많을수록 비싸겠지만, 비싼 차들은 좌석이 두개만 있는 경우도 있고 아무래도 넓은 공간을 위해 좌석이 적은 경우도 있다.
- New_Price
신차가격, 가장 중고차 가격을 결정하는데 좋은 지표가 아닐까 싶다. 단위는 인도화폐 단위인 ‘라크’로 되어있다.
- Price
우리가 예측해야 할 타겟 값
특성 별 데이터를 대략 살펴봤으니
먼저 트레인셋을 또 한번 트레인셋과 테스트셋으로 나눠준다.
이제 데이터를 불러와, 데이터들의 타입과 결측치에 대해 알아보아야 한다.
1
2
3
4
5
6
import pandas as pd
train = pd.read_csv('train-data.csv')
test = pd.read_csv('test-data.csv')
train.info()
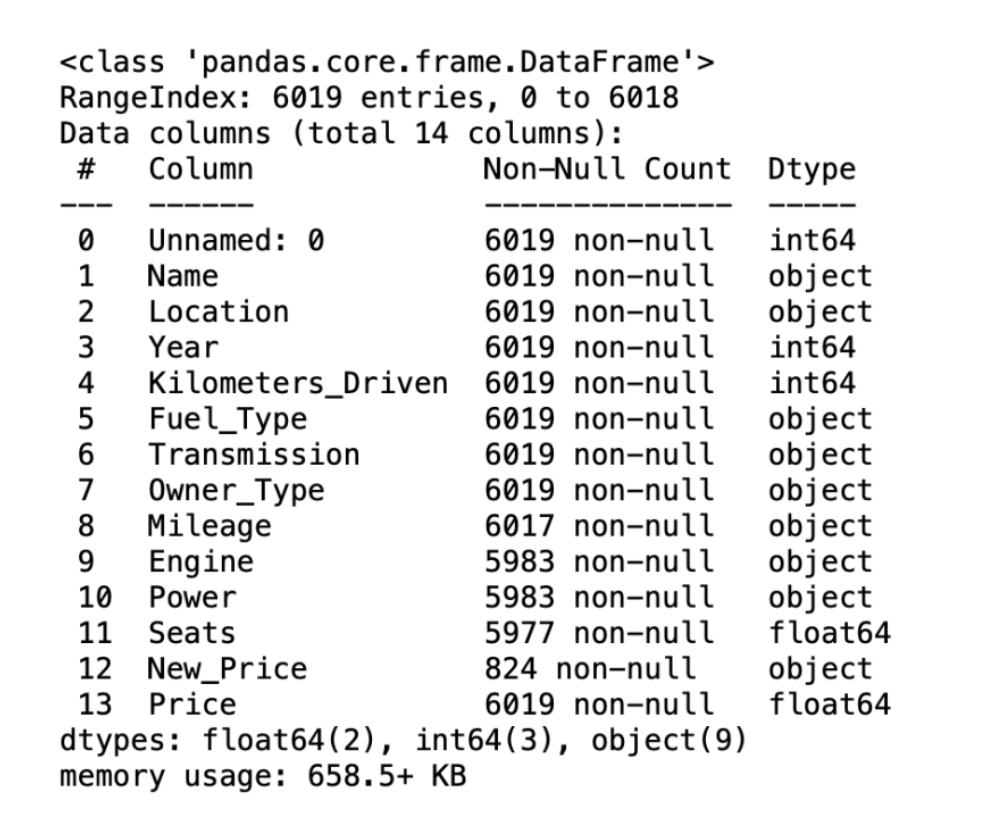
이 데이터셋은 6019개의 데이터로 이루어져 있으며,
엔진과 마력, 좌석개수, 신차가격은 결측치가 꽤 있는데
그 중에서 신차가격은 타겟과의 연관성이 매우 높게 보이는 데이터임에도 불구하고 결측치가 너무 많다.
먼저 대략적으로 그래프를 그려 가격과의 상관관계를 알아보자.
Name의 특성부터 처리해보자
Name은 회사명만을 남기고 뒤의 글자는 삭제 해주도록 하자.
1
train['Name'].str.extract('([A-Za-z]+).')
str.extract는 정규표현식을 사용하여 문자를 추출해준다.
[A-Za-z]는 문자를 대소문자 관게없이 하나를 추출하는데, +가 붙으면 단어 단위로 추출한다.
우리는 맨앞의 회사명만을 추출하면 되므로 맨앞 단어를 추출하는 정규표현식을 사용해준다.
1
train['Name'] = train['Name'].str.extract('([A-Za-z]+).')
Location 부터 Ownertype은 결측치도 없고 데이터 자체도 깔끔하여 따로 손댈 곳이 없어보인다.
Mileage의 경우에는 2개의 데이터 결측치가 있다. 이 두개의 차종을 불러와보면,
python
train[train['Mileage'].isnull()==True]
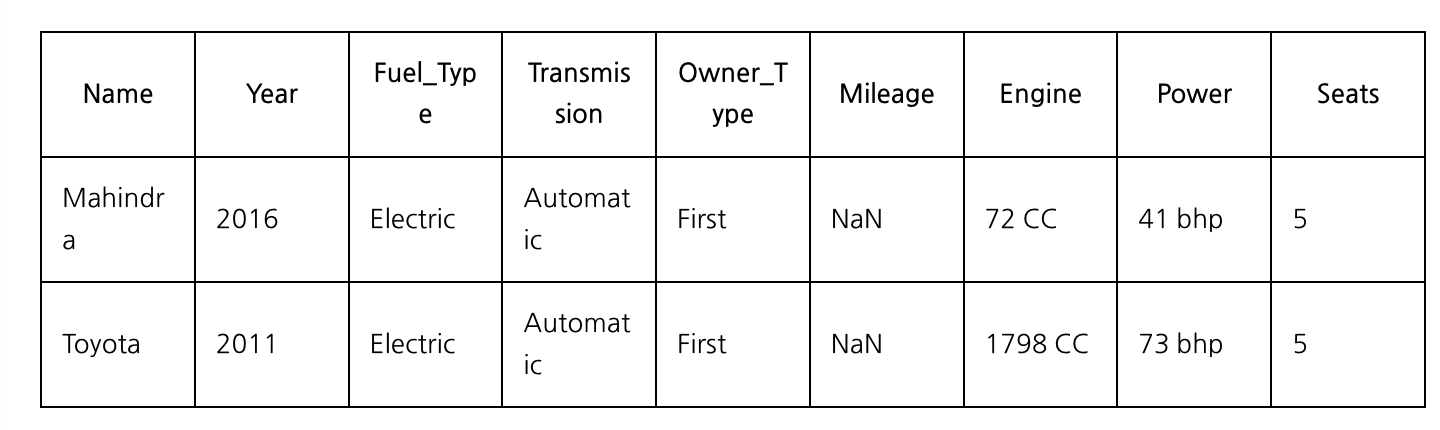
원래 생각은 이 차의 데이터를 불러와 연비에 영향을 미칠만한 데이터를 몇가지 뽑아본뒤 이 데이터에 있는 다른 차량이랑 비교하여 대략 연비 결측치를 채우려 했는데, 두 차종은 이 데이터에 유일하게 두개있는 전기차이다.
인터넷에 검색하여 이 차종들의 연비를 직접 검색해보도록 해서 채우도록 해보았다.
먼저 도요타 프리우스 2011년식은 하이브리드 차량이라 연비가 존재한다. 프리우스의 연비는 29.3이다.
마힌드라 E verito D4의 경우는 인도차량인데, 전기차라서 연비가 리터당이 아니라 완충시 거리로 나타나있다.
이러한 경우는 연비의 단위가 달라서 좀 골치가 아픈데, 어차피 이 데이터가 1개밖에 없기 때문에 전체 모델에 미치는 영향은 아주 미미할것 같아, 마힌드라 차량의 데이터는 그냥 지우도록 결정했다.
1
2
train.loc[4446,'Mileage'] = 29.3
train['Mileage'].dropna()
또, Mileage의 데이터를 보면 연비가 0.0 kmpl인 차량들이 있다.
이러한 이상치들도 보정을 해주어야 하는데, 이상치를 가진 데이터의 숫자가 68개로 꽤나 많았다.
68개의 데이터를 모두 세세히 최대한 의미있는 값으로 채우는건 힘들것 같아서 연비의 중앙값으로 우선 채운뒤 나중에 모델의 성능이 떨어지면 그 때 더 세세한 전처리를 해보도록 할 것이다.
우선 연비의 데이터타입을 숫자로 바꾼 뒤, 연비가 0인값에 중앙값을 대입해주자.
1
2
3
4
5
train['Mileage'] = train["Mileage"].str.extract('([0-9]+\.[0-9]+)')
train['Mileage'] = train['Mileage'].astype(float)
train[train['Mileage']==0] = train['Mileage'].median()
다음은 Engine이다. 먼저 Engine의 결측치들을 불러와 어떻게 처리하면 좋을지 생각해보자.
Engine 특성에 결측값이 있는 데이터들은 모두 Power 특성도 결측되어있다.
Simple Imputer 를 통해 중앙값으로 채워주도록 하자.
마찬가지로 계산을 위해 단위를 떼고 숫자를 float형으로 변환 후, 숫자형 데이터만 모아 결측치를 채워주자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
train['Power'] = train["Power"].str.extract('([0-9]+\.[0-9]+)')
train['Power'] = train['Power'].astype(float)
train['Engine'] = train['Engine'].str.extract('([0-9]+)')
train['Engine'] = train['Power'].astype(float)
train_num = train.drop(['Name', 'Location', 'Fuel_Type', 'Transmission', 'Owner_Type','New_Price'], axis = 1)
test_num = test.drop(['Name', 'Location', 'Fuel_Type', 'Transmission'], axis = 1)
X = imputer.fit_transform(train_num)
y = imputer.fit_transform(test_num)
train_num = pd.DataFrame(X, columns = train_num.columns, index = train_num.index)
test_num = pd.DataFrame(y, columns = test_num.columns, index = test_num.index)
숫자형 데이터들의 단위를 빼주고 SimpleImputer를 사용하여 결측치를 채웠으니,
숫자형데이터들을 matplotlib으로 시각화하여 보기로 하자.
1
2
3
4
5
plt.figure(figsize=(20,10))
for i in range(0,6):
plt.subplot(2,3,i+1)
plt.scatter(train_num.iloc[:,i], train_num['Price'])
plt.title(train_num.columns[i])
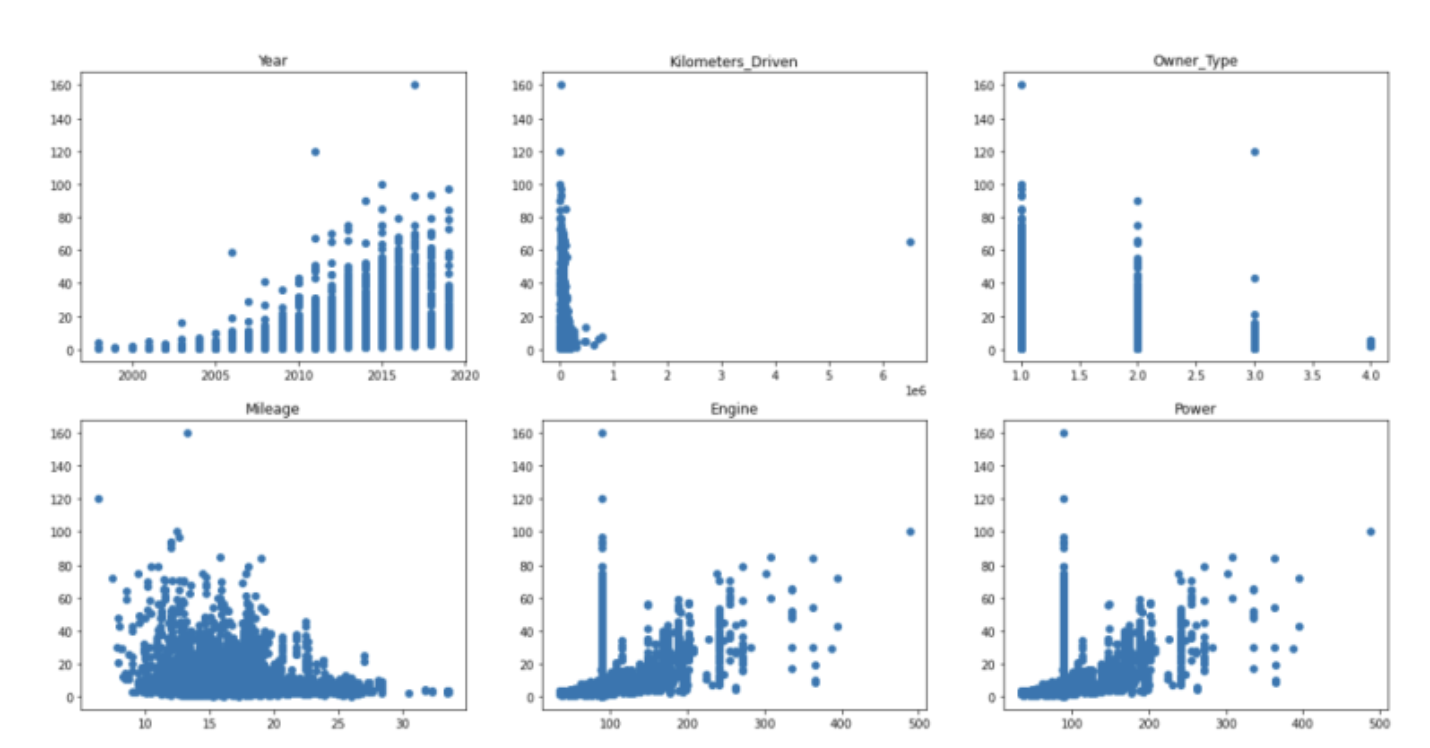
시각화 해보니, Kilometers_Driven의 그래프가 이상하다.
말도 안되게 큰값이 하나 섞여있는 것 같다.
아마 데이터 입력과정에서 0을 하나 잘못입력 한것 같은데, 6000000이 넘는 데이터를 찾아보자.
python
train_num[train_num['Kilometers_Driven']>6000000]

2328번 행의 값이 650만이라는 비정상적인 이상치를 갖고있다.
0을 하나 잘못입력했다고 생각하고 0을 하나 뺴줄 수도 있겠지만,
그냥 행자체를 삭제 해주도록 하자. _num에서 행을 지웠으면, _cat에서도 지워야 한다.
그렇지 않으면 나중에 두 데이터들을 합칠때, 숫자형데이터에 결측치가 있는 상태로 2328의 _cat 행과 합쳐진다.
1
2
train_num.drop(2328, inplace= True)
train_cat.drop(2328, inplace= True)
다시 그래프를 그려보면,
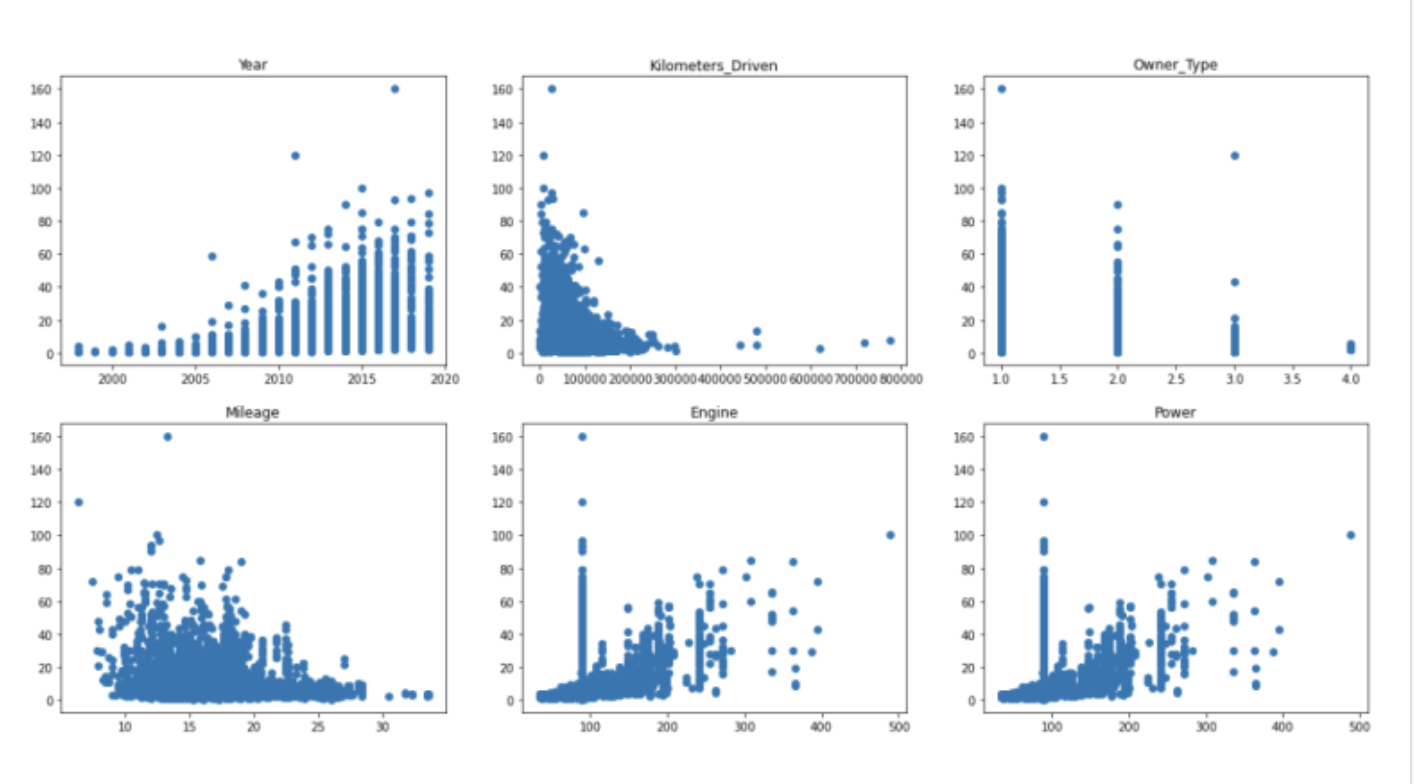
이상치가 없어져, Kilometers_Driven이 정상적인 모습을 듸는것을 알 수 있다.
그 밖의 다른 데이터들을 보면 동일한 중앙값으로 결측치를 채웠기 때문에 기둥모양의 데이터가 분포되어 있는 것을 볼 수 있다.
이제 숫자형 데이터를 어느정도 처리했으니, 범주형 데이터를 처리해주자.
python
train_cat = train_cat.astype(str)
test_cat = test_cat.astype(str)
전처리 전에, 범주형 데이터들을 모두 str타입으로 변환해준다.
그 후, 범주형 데이터의 컬럼들을 따로떼어나 각각의 데이터프레임 객체로 저장한뒤, get_dummies 메서드를 이용해 범주형 데이터들을 더미변수화 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
name = pd.DataFrame(train_cat.iloc[:,0])
loc= pd.DataFrame(train_cat.iloc[:,1])
fuel = pd.DataFrame(train_cat.iloc[:,2])
trans = pd.DataFrame(train_cat.iloc[:,3])
namet = pd.DataFrame(test_cat.iloc[:,0])
loct = pd.DataFrame(test_cat.iloc[:,1])
fuelt = pd.DataFrame(test_cat.iloc[:,2])
transt = pd.DataFrame(test_cat.iloc[:,3])
name = pd.get_dummies(name, drop_first= True)
loc = pd.get_dummies(loc, drop_first= True)
fuel = pd.get_dummies(fuel, drop_first= True)
trans = pd.get_dummies(trans, drop_first= True)
namet = pd.get_dummies(namet, drop_first= True)
loct = pd.get_dummies(loct, drop_first= True)
fuelt = pd.get_dummies(fuelt, drop_first= True)
transt = pd.get_dummies(transt, drop_first= True)
이렇게 더미변수화한 각각의 칼럼들을 다시 train_cat이라는 범주형 변수로 합쳐준다.
숫자형 데이터는 astype을 통해 float형으로 통일해준다.
1
2
3
4
train_cat = pd.concat([name,loc,fuel,trans], axis = 1)
test_cat= pd.concat([namet,loct,fuelt,transt], axis = 1)
train_num = train_num.astype(float)
test_num = test_num.astype(float)
그럼 숫자형 데이터를 모델의 학습을 위해 동일한 스케일로 바꿔주자.
1
2
3
4
5
6
from sklearn.preprocessing import StandardScaler
std = StandardScaler()
train_scaled = std.fit_transform(train_num)
test_scaled = std.fit_transform(test_num)
StandartdSclaer를 통해 숫자형 데이터들을 표준화하여 스케일을 맞춰준다.
이러한 데이터들은 _scaled 로 저장해준다.
그럼 어느정도 전처리가 끝났으니, _num과 _cat을 하나의 데이터로 합쳐 머신러닝 모델에 학습 후, 성능을 확인해보도록 하자.
python
train_prepared = pd.concat([train_scaled, train_cat], axis =1)
train_labels = train_prepared['Price']
train_prepared.drop('Price', inplace= True, axis =1)
학습을 위해 _prepared로 숫자형 데이터와 범주형 데이터들을 합쳐주고, 우리의 타겟값인 Price를 따로 떼어 train_lables로 따로 저장한다.
먼저 가장 기본적인 모델인 LinearRegression 모델에 학습 시킨 후 점수를 출력해보자.
```python
from sklearn.linear_model import LinearRegression
linear = LinearRegression()
linear.fit(X_train,y_train)
linear.score(X_train, y_train)
```
——
0.739798783283754
약 74퍼센트의 정확도를 보였다.
74 퍼센트면 나쁘진 않지만 실제로 예측을 위해서 사용하기에는 무리가 있는 수치이다.
이렇게 컬럼이 많은 데이터는 보통 랜덤포레스트 모델을 사용하면 좋은 성능을 얻을 수 있다고 한다.
그럼 더 좋은 성능을 위해 랜덤 포레스트 모델을 적용시켜 보도록 하자.
1
2
3
4
5
from sklearn.ensemble import RandomForestRegressor
rfr = RandomForestRegressor(random_state= 23)
rfr.fit(X_train, y_train)
rfr.score(X_train,y_train)
0.9777049415675514
랜덤 포레스트 모델은 97.7 퍼센트의 정확도를 보여준다.
이 정도면 너무 휼륭한 값이다. 오버피팅 된건 아닌지, 교차검증을 통해 다시 한번 정확도를 확인해보도록 하자.
1
2
3
4
from sklearn.model_selection import cross_val_score
cross_val_score(rfr,X_train, y_train, cv = 3)
array([0.80580289, 0.82602464, 0.85854635])
3번의 폴드가 모두 80퍼센트 이상의 값을 가졌는데, 이정도면 오버피팅의 걱정도 크게 없을정도로
괜찮은 값인 것 같다. 그렇다면 우리가 나눠놓은 테스트셋을 넣어 모델의 예측정확도를 확인해보자.
1
rfr.score(X_test,y_test)
0.8478642602832028
테스트셋에서도 약 85퍼센트에 가까운 정확도를 보여주었다.
이로써 우리는 85퍼센트 성능의 정확도를 보이는 예측 모델을 만들었다.
마무리
이렇게 그동안 배운 내용을 적용해서 캐글에 있는 데이터를 직접 전처리하고 모델을 적용해보았다. 사실 원래는 모델이야 지식이 없으니 어떤 모델을 사용할지는 인터넷의 도움을 받고, 전처리는 그래도 내 생각만으로 처리해보고자 했는데 생각보다도 더 어려워서 몇개의 아이디어는 인터넷의 도움을 받았다…
그래도 이런 데이터 전처리 과정을 경험해보니 나름 결측치를 찾고 이를 어떻게 보정할지에 대해 고민하며 그 방법을 적용하면 실제로 예측치 성능이 오르는게 재밌었다.
특히 전기차에 대한 부분을 기름에 대한 연비로 변환하여 적용해보는 방식이 제일 인상깊었는데, 만약 이를 기반으로 파이프라인을 만든다면 전기차의 연비를 기름의 연비로 변환하는 식을 추가함으로써 새로운 전기차가 생겨도 자동으로 해당 데이터를 기름에 대한 연비로 수집 하도록 해볼 수 있을 것 같다. 어쩌면 미래에는 전기차에 대한 데이터가 더 많아져서 기름에 대한 연비를 전비로 바꿔야 할 필요성이 생기겠다는 생각도 해봤다.
뭐 이정도 가지고 머신러닝을 공부했다고 하기는 그렇지만, 적어도 평소에 궁금했던 머신러닝이 대략 어느정도의 프로세스를 갖고 그런 퍼포먼스를 내는지 알게 되었다.
막상 해보니 ‘인공지능’이라는 말이 걸맞는 수준의 놀라운 마법같은 일인지는 모르겠지만 그래도 이러한 방법론들을 기반으로 정말 인공지능이란 말이 걸맞는 수준의 성능을 내는 시대가 얼마지나지 않아 올것이라는 생각이 든다!
댓글남기기