
[Spring] 다대다 관계 맵핑
서론
JPA 를 사용하다 보면, 여러가지 복잡한 테이블 관계를 만나게 됩니다. 특히, 다대다 관계는 서로가 서로를 맵핑하기 때문에 단순하게 서로가 서로를 갖도록 구현하면 여러가지 에러를 만날 수 밖에 없게 됩니다.
제가 개발을 하다가 맞닥뜨린 문제를 함께 해결해보면서, JPA에서의 다대다 관계는 어떻게 구현하는게 가장 안전하고 효율적인 방법인지 함께 알아보도록 합시다.
@ManyToMany
제가 만드는 웹페이지는 봉사 동아리의 봉사 신청을 주 기능으로 갖고 있는데요, 봉사를 신청한 유저가 해당 봉사 페이지에 보이는 동시에, 해당 유저의 정보 페이지에서는 유저가 그동안 신청했던 봉사 내역을 출력하도록 하고 싶었습니다.
봉사라는 객체도 유저를 일대다 관계로 갖고, 유저라는 객체도 봉사를 다대일로 갖게되는 상황이 된것입니다.
만약 단순하게 이 둘을 다이렉트로 다대다 관계로 맵핑하고, 이를 데이터베이스에서 호출 한다면 어떻게 될까요?
봉사를 호출한다고 가정하면, 봉사를 호출하면 그 안에있는 유저들을 호출하고, 그 유저들안에 있는 봉사를 또 호출하고, 또 다시 그 유저안에 있는 봉사를 호출하고….
이런식으로 무한 호출이 발생할 것입니다.
그래서 스프링의 @ManyToMany 어노테이션을 사용할때는, 반드시 @JoinTable을 사용해서 중간 테이블을 하나 만들도록 해야합니다.
예를 들어, 위에서 제가 구현하려고 한 봉사와 유저를 다대다로 맵핑한다면, 아래와 같이 연결 테이블을 생성해서 다대다로 맵핑하게됩니다.
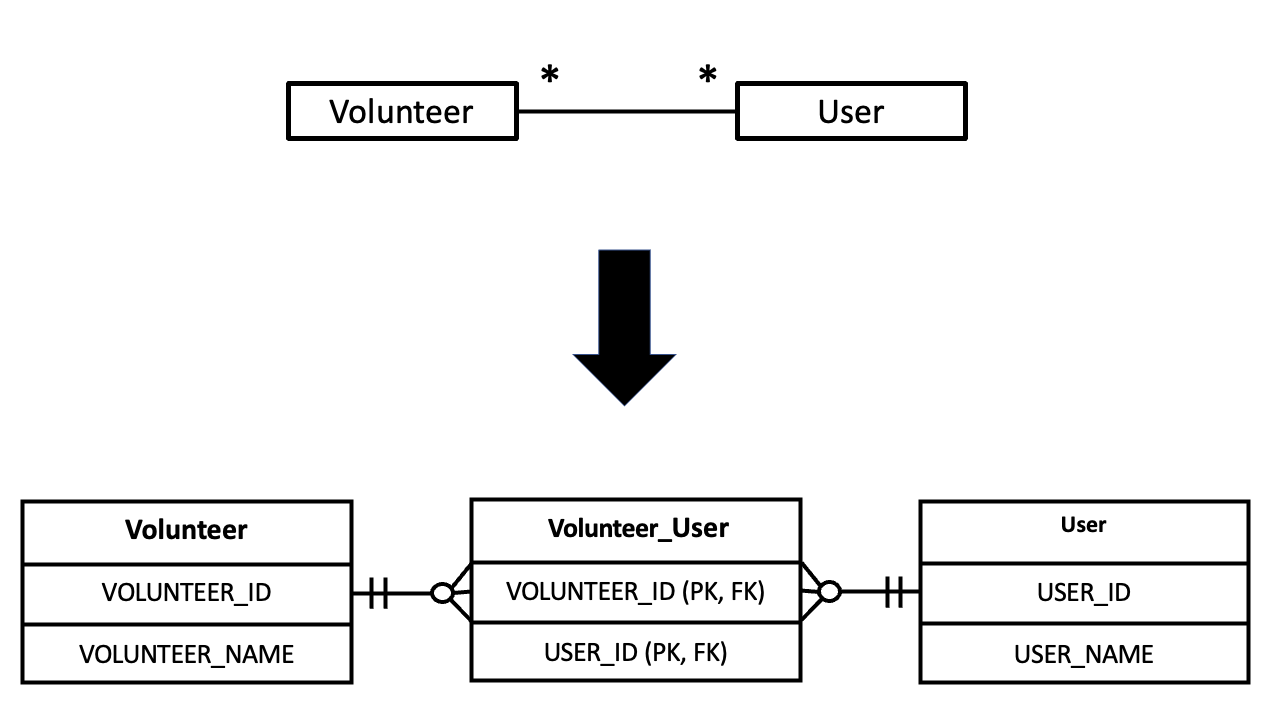
하지만 이렇게 @ManyToMany로 맵핑하는것은 지양해야합니다. 왜냐하면 연결테이블이 생기면 대부분의 상황에서 이 연결테이블의 생성시간이라던가, 변경시간, 혹은 여러가지 추가 데이터를 추가 해야할일이 생기는데, @ManyToMany의 연결 테이블에서는 이러한 것들을 추가할 수가 없습니다.
게다가 중간 테이블의 id값이 어디에 종속적으로 된다는 것은, 유지보수에 있어 좋지 않습니다. 모든 테이블은 각자의 고유한 아이디를 갖는 것이 효율적입니다.
따라서 @ManyToMany는 아예 사용하지 않는것이 가장 좋습니다.
그렇다면 이러한 다대다 관계는 JPA에서 어떻게 구현하는 것이 가장 효율적일까요?
다대다 한계 극복하기
이러한 문제들을 해결하기 위해서는, 중간테이블을 @ManyToMany가 생성하게해서 다대다 맵핑 하는 것이아니라, 직접 테이블을 만들고 이를 @OneToMany와 @ManyToOne 으로 맵핑해주는 것이 안전하고 효율적입니다.
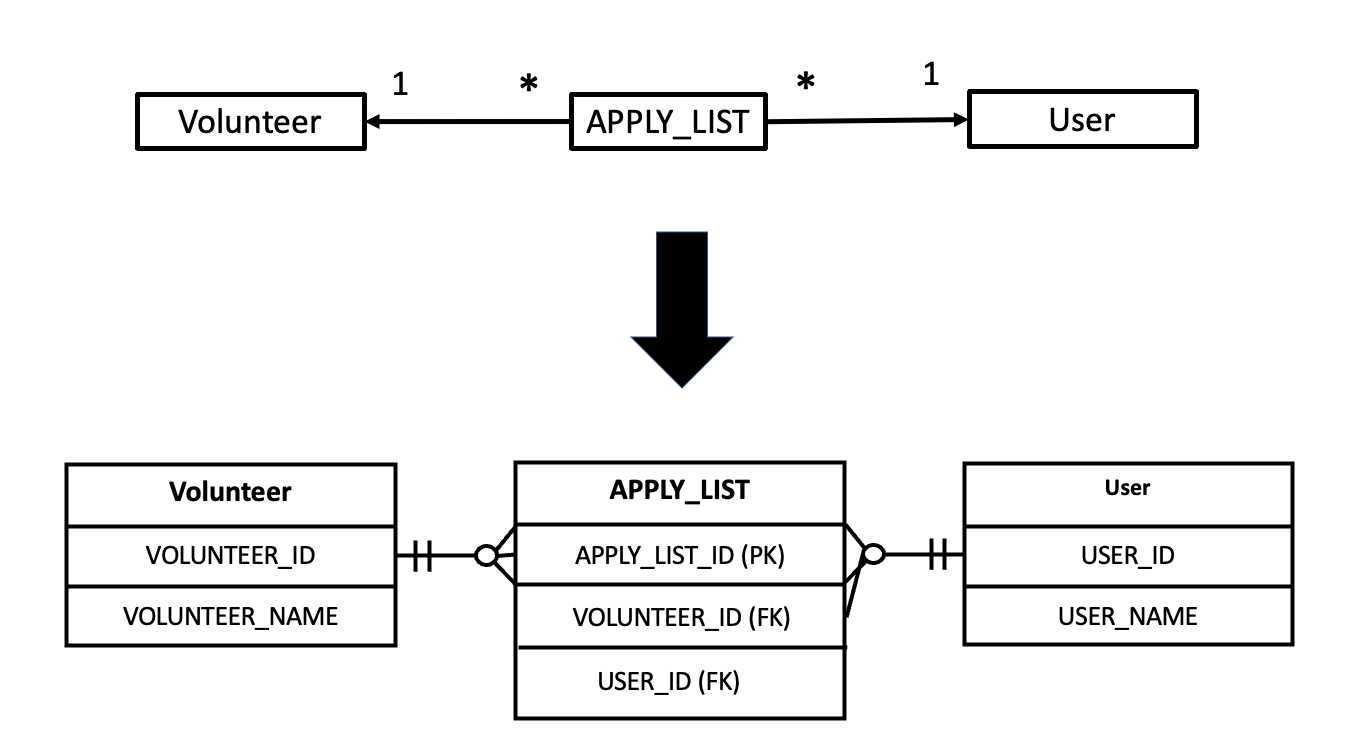
이렇게 중간 테이블인 ARRAY_LIST를 JPA에서 자동 생성해서 다대다 맵핑하는것이 아니라, 직접 PK가 있는 테이블로 만들어 이를 각각 테이블에 다대일 관계로 맵핑해주는 것입니다.
코드로 한번 보도록 합시다. 실제 제가 구현한 코드를 알아보기 쉽게 간소화해서 작성했습니다.
@ManyToMany를 사용한 코드
Volunteer
1
2
3
4
5
6
7
8
9
10
11
12
13
14
@Getter
@NoArgsConstructor
@Entity
public class Volunteer extends BaseTimeEntity {
@Id
@GeneratedValue(strategy = IDENTITY)
private Long id;
private String title;
@ManyToMany
@JoinTable("APPLY_LIST")
private List<User> users = new ArrayList<>();
}
User
1
2
3
4
5
6
7
8
9
10
11
12
13
@Getter
@NoArgsConstructor
@Entity
public class User extends BaseTimeEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@ManyToMany(mappedBy = "users")
private List<Volunteers> volunteers = new ArrayList<>();
}
위처럼 하면 @ManyToMany를 사용해서 다대다 맵핑을 완료할 수 있습니다.
하지만 위에서 @ManyToMany를 사용하는 것은 지양해야한다고 했습니다. 그럼 이번에는 중간테이블을 직접 엔티티로 승격시켜 @ManyToMany를 사용하지 않고 코드를 작성해봅시다.
Volunteer
1
2
3
4
5
6
7
8
9
10
@Getter
@NoArgsConstructor
@Entity
public class Volunteer extends BaseTimeEntity {
@Id
@GeneratedValue(strategy = IDENTITY)
private Long id;
private String title;
}
User
1
2
3
4
5
6
7
8
9
10
@Getter
@NoArgsConstructor
@Entity
public class User extends BaseTimeEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
}
ApplyList
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
@Getter
@NoArgsConstructor
@Entity
public class ApplyList extends BaseTimeEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@ManyToOne
@JoinColumn
private User user;
@ManyToOne
@JoinColumn
private Volunteer volunteer;
}
이렇게 다대다 연관관계를 지워주고, 중간테이블을 Entity로 승격시켜 각각 ManyToOne으로 다대일 연관관계로 맵핑하면 됩니다. 양방향으로 맵핑이 굳이 필요하지 않다면, 단방향으만 맵핑해주는게 좋습니다.
Service 레이어 코드 작성하기
그렇다면 이 상태에서 User를 조회했을때 해당 User가 신청한 봉사가 나오고, Volunteer를 조회했을 때 해당 봉사를 신청한 유저가 나오게 하려면 서비스 레이어를 어떻게 작성해야 할까요??
두가지 방법이 있습니다.
- 양방향으로 맵핑하기
- 단방향으로 직접 ApplyList를 조회하여 DTO로 반환하기
하지만 1번의 경우, 위 코드에서 양방향 맵핑을 하게되면 ApplyList에는 User와 Volunteer가 모두 있으므로 자신이 자신을 계속 참조하는 순환 참조에 빠져 스택 오버플로우가 일어나게됩니다.
아니면 @JsonManagedReference와 @JsonBackReference를 사용해서 직렬화를 하지 않도록 설정 해주어서 순환 참조를 막는 방법이 있습니다.
하지만 굳이 양방향 맵핑을 사용해서 DB를 복잡하게 하고 순환 참조의 위험을 감수하는것 보다는, 단방향 맵핑 그대로 DTO를 사용해서 처리하는게 가장 바람직합니다.
한번 코드로 보도록 합시다.
VolunteerService
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
public class VolunteerService {
private final VolunteerRepository volunteerRepository;
private final ApplyListRepository applyListRepository;
@Transactional
public VolunteerArticleDto findById(Long id) {
Volunteer entity = volunteerRepository.findById(id)
.orElseThrow(
() -> new NoExistVolunteerException()
);
List<ApplyList> applyLists = applyListRepository.findByVolunteer(entity);
List<User> applicants = applyLists.stream()
.map(ApplyList::getUser)
.collect(Collectors.toList());
return VolunteerArticleDto.builder()
.entity(entity)
.applicants(applicants)
.build();
}
}
UserService
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
public class UserService {
private final UserRepository userRepository;
private final ApplyListRepository applyListRepository;
@Transactional
public UserResponseDto findById(Long id) {
Optional<User> user = userRepository.findById(id);
if (!user.isPresent()) {
throw new NoExistUserException();
}
List<ApplyList> applyLists = applyListRepository.findByUser(user.get());
List<Volunteer> volunteers = new ArrayList<>();
for (ApplyList apply : applyLists) {
volunteers.add(apply.getVolunteer());
}
return UserResponseDto.builder()
.entity(user.get())
.volunteers(volunteers)
.build();
}
}
UserResponseDto와 VolunteerArticleDto를 만들어줌으로써, 필요한 데이터만을 담는 DTO를 생성해주고, applyListRepository에서 직접 조인해서 해당 id에 맞는 봉사와 유저정보를 가져와 Dto에 담아주면 됩니다.
이렇게 하면 다대다 관계를 @ManyToMany 없이 순환참조를 없앤 상태로 구현할 수 있습니다. 또한, 굳이 양방향 맵핑을 해주지 않음으로써 테이블의 복잡도도 낮출 수 있죠.
마무리
오늘은 이렇게 @ManyToMany를 사용하지 않고 중간테이블을 만들어 줌으로써 양방향 맵핑을 각각의 단방향 맵핑으로 구현하여 해결해보았습니다.
JPA는 객체지향적으로 데이터베이스와 객체를 맵핑하도록 도와주지만, 여러가지 알아야 할 것들이 참 많은 것 같습니다. 존재는 하지만 실무에서 절대 사용해야할 주의사항도 많아서, 스프링 문서만 읽어보고 아 이런기능이 있구나~ 하고 사용하다가는 큰 문제를 만날 수 있으니, 꼭 자세하게 배워 사용할 수 있는 능력이 필요할 것 같습니다.
댓글남기기