
커넥션 풀
커넥션 풀은 왜 필요할까?
웹 서버가 DB와 연결을 하는것에는 생각보다 많은 비용이 들어갑니다.
만약 JDBC를 통해 DBMS와 연결을 할떄는 , 다음과 같은 과정을 거칩니다.
- DB벤더에 맞는 드라이버 로드
- DB서버의 IP, ID, PW등을 DriverManager 클래스의 getConnection 메소드를 사용하여 Connection 객체 생성
- Connection으로 부터 PreparedStatement 객체를 받음
- executeQurey를 수행하고 ResultSet객체를 받아 데이터를 처리
- 사용했던 ResultSet, PreparedStatement, Connection을 close
이 과정중에서 2번에서 커넥션 객체를 생성하고 얻어오는 부분은 DB서버와 애플리케이션과의 통신이 필요하기 때문에
위 과정중에서 가장 무겁고 오래 걸리는 작업입니다.
따라서 만약 매 요청마다 이 과정을 반복한다면, 당연히 훨씬 더 많은 시간과 자원을 소모하게 될 것입니다.
누구도 요청을 보낼때마다 몇초씩 걸리는 느린 웹서버를 사용하고 싶지는 않겠죠?
그래서 나온 방법이 바로 커넥션 풀 (Connection Pool)입니다.
커넥션 풀
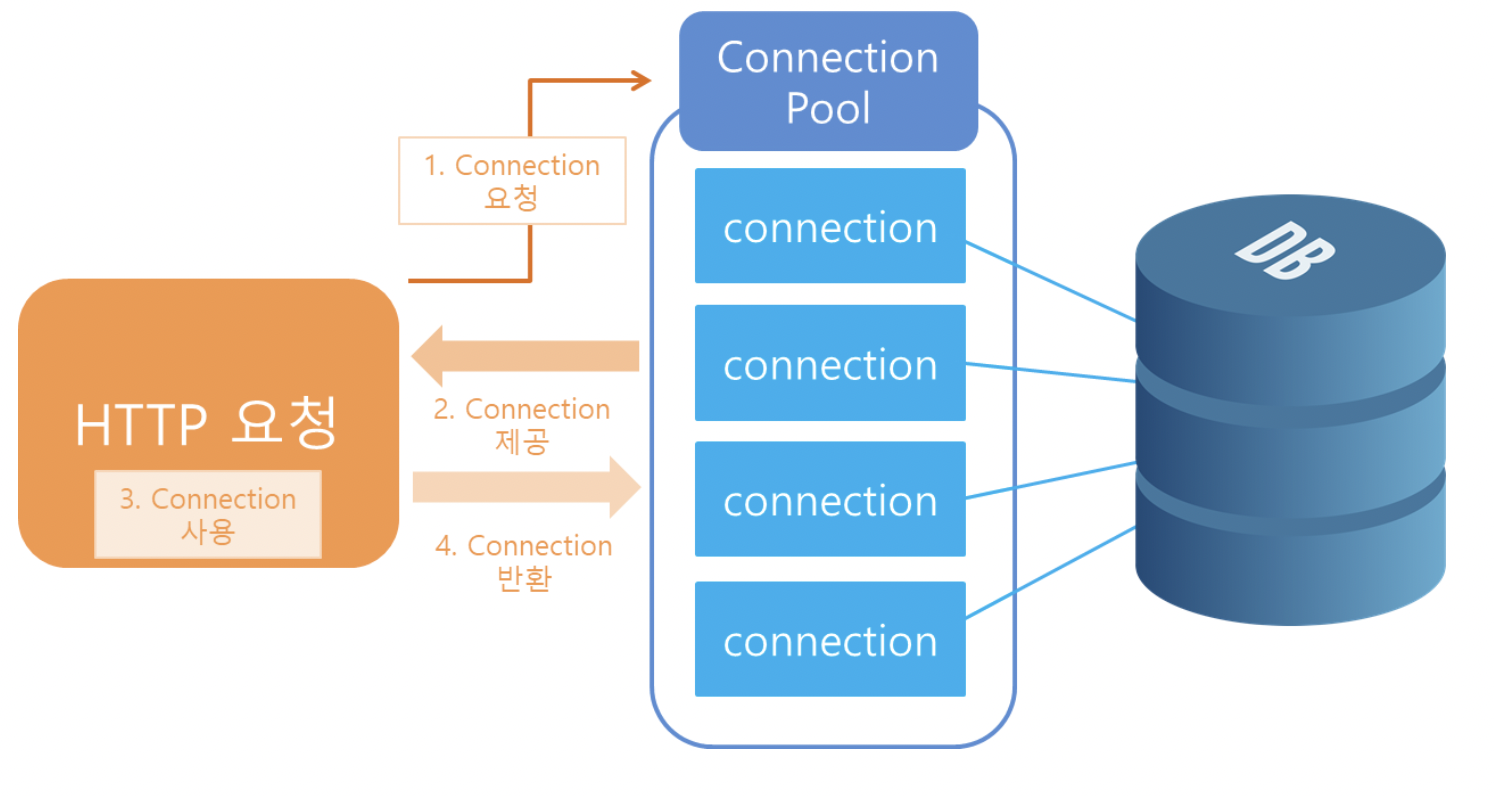
커넥션 풀은 말그대로 커넥션들이 있는 공간입니다. WAS가 실행되면서 DB와 미리 커넥션 해놓은 객체를 커넥션 풀에 저장해놨다가, 클라이언트에서 요청이 들어오면 커넥션을 빌려주고, 처리가 끝나면 다시 커넥션을 받아서 커넥션 풀에 다시 저장해 놓습니다.
이렇게 미리 WAS가 실행될때 미리 커넥션 객체를 생성하고 이를 받아오기만 한다면, 위 과정에서의 2번에 드는 자원과 시간을 매우 효율적으로 사용할 수 있을 것입니다.
따라서 커넥션 풀은 아래와 같은 특징을 갖습니다.
- WAS가 실행되면, 커넥션 객체를 미리 커넥션풀에 생성
- HTTP 요청으로 커넥션 풀에서 커넥션 객체를 받아 사용한다.
- 사용이 끝나면 다시 해당 커넥션 객체를 커넥션 풀에 반환한다.
- 이때, 커넥션 객체들은 이미 연결을 마친 채로 커넥션 풀에 저장되어 있는 것이기 때문에, 커넥션을 연결하는 시간이 소요되지 않는다.
- 커넥션을 계속해서 재사용하기 때문에 생성되는 커넥션 수는 제한적이다.
여기서 마지막 줄을 보면, 커넥션 수는 제한적인 특징을 갖습니다.
따라서 커넥션 개수보다 많은 요청이 한꺼번에 들어온다면, 커넥션이 풀에서 모두 동나는 상황이 발생하게 될 것입니다. 이럴 때 커넥션 풀은 어떻게 동작할까요?
커넥션이 없는 상태에서 요청이 들어오면, 해당요청에 번호를 매긴 상태로 대기하도록 합니다. 빌려간 커넥션이 다시 반환되면, 대기하고 있는 클라이언트에게 순서대로 다시 커넥션을 제공 하는 것이죠.
우리가 가끔 정각에 쿠폰을 제공하는 이벤트나 티켓팅을 할 때 홈페이지가 느리게 뜨거나 요청이 느려지는 것도, 이러한 커넥션이 부족하기 때문에 발생하는 현상 중 하나입니다.
그럼 이러한 의문점이 들 수 있습니다.
커넥션을 무조건 많이 만들면 좋은거 아니야?
물론 커넥션 풀을 크게 하면 그만큼 줄 수 있는 커넥션의 수가 늘어남으로, 더 많은 요청을 처리하는 것이 가능해집니다. 하지만 커넥션 풀이 커질 수록 메모리 소모가 커지기 때문에, 자신이 가진 서버의 스펙등을 고려하여 알맞게 설정해 주어야 합니다.
또한, WAS에서 사용하는 커넥션을 사용하는 주체는 결국 스레드 (Thread)이기 떄문에, WAS가 가진 스레드 풀보다 커넥션풀의 크기가 크다면, 남는 커넥션들은 생성되어 메모리를 소모하면서, 정작 사용되지도 못하여 성능만 잡아 먹는 경우가 발생합니다.
그럼 스레드 풀의 크기와 커넥션 풀의 크기를 둘다 늘려준다면???
이 경우에도 스레드는 컨텍스트 스위칭을 하기 때문에 결국 한계가 존재하고, 데이터베이스 입장에서도 커넥션이 단순히 많기만 한다고 성능이 비약적으로 올라가는 것도 아니기 때문에, 이상적인 스레드와 커넥션의 수는 해당 애플리케이션과 DB의 스레드, 커넥션의 수가 CPU의 코어 수가 동일할때 라고 할 수 있습니다.
물론 실제로는 CPU의 성능이 많이 좋아졌기 때문에 코어 개수보다 더 여유있게 커넥션풀의 크기를 설정합니다.
그렇다면 이상적인 커넥션풀의 크기는?
스프링에서는 Hikari CP (Hikari Connection Pool) 사용하여 커넥션풀을 관리합니다. HikariCP는 매우 적은 130kb의 용량으로 압도적은 빠른 속도를 제공하는 JDBC의 커넥션 풀 프레임 워크입니다.
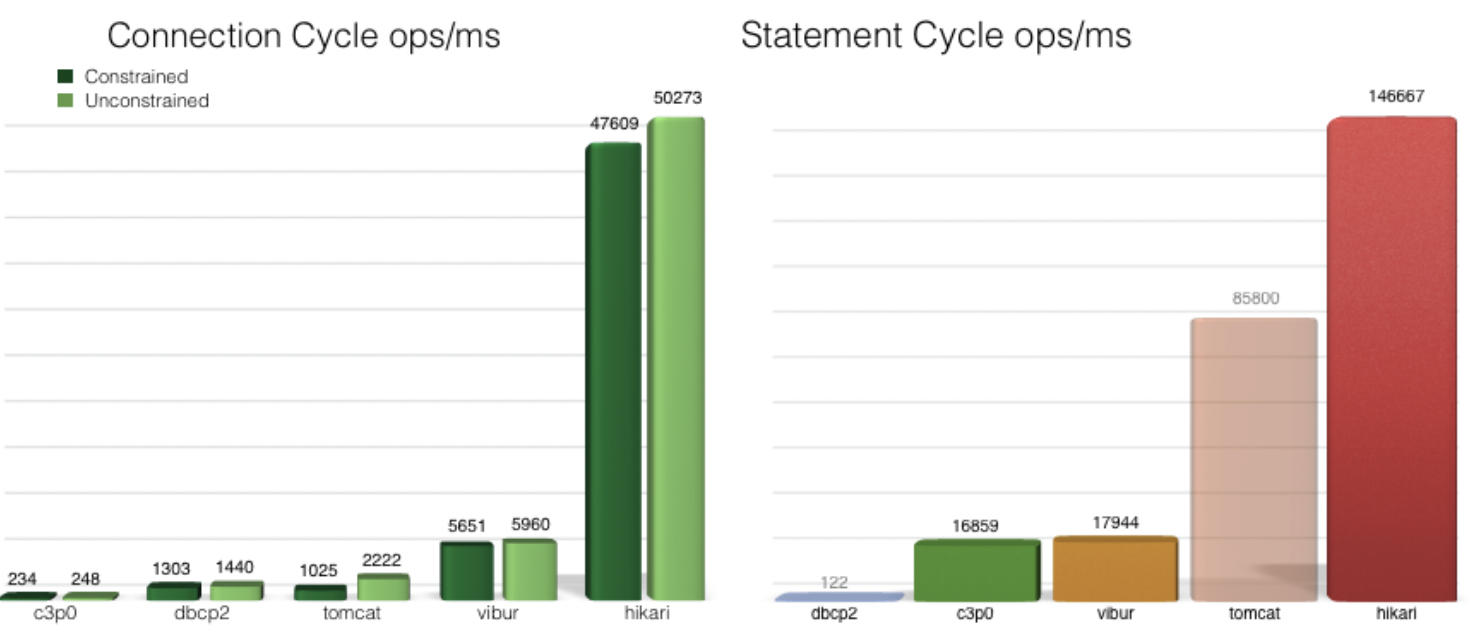
Hikari CP에서 제공하는 벤치마크를 보면, 따른 커넥션풀 프레임워크들에 비해 압도적인 최적화 성능을 자랑합니다. 따라서 스프링부트도 2.0버젼부터는 기존에 사용하던 Tomcat을 HikariCP로 변경했습니다. 따라서 의존성에 기본적으로 spring-boot-starter-data-jpa나 spring-boot-starter-jdbc 의존성을 포함할 경우, 자동으로 HikariCP가 포함됩니다.
그렇다면 HikariCP에서 공식문서에서 추천하는 이상적인 커넥션 풀의 크기는 얼마일까요??
ikari CP의 공식문서에 따르면 connections = ((core_count * 2) + effective_spindle_count)라고 명시되어 있습니다.
여기서 말하는 core_count는 서버의 논리 CPU개수를 말합니다. 위에서 말했듯이 컨텍스트 스위칭으로 인한 한계를 고려하더라도, 데이터베이스의 디스크 읽기 쓰기나 DRAM이 데이터를 처리하는 속도보다 CPU의 속도가 월등히 빠르기 때문에, 데이터베이스가 필요한 데이터를 찾는동안 갖는 대기시간에 CPU는 작업 스레드를 변경해 더 많은 요청을 수행할 수 있습니다.
effective_spindle_count는 하드 디스크와 관련이 있습니다. 하드 디스크 하나는 spindle 하나를 가집니다.
이에 따라 spindle의 수는 기본적으로 DB 서버가 관리할 수 있는 동시 I/O 요청 수를 말합니다. 디스크가 16 개가 있는 경우 시스템은 동시에 16 개의 I/O 요청을 처리할 수 있습니다. 물론 RAID 구성 방식에 따라서 달라질 수 있습니다. 해당 공식에서 디스크의 효율을 고려하여 spindle_count를 더해준 것으로 보입니다.
최종적으로 CPU의 처리 효율과 디스크 처리 효율을 고려한 결과, **((core_count * 2) + effective_spindle_count) **공식을 통해 Connection의 개수를 추정할 수 있다고 알게 되었습니다.
당연히 이러한 공식이 무조건 모든 상황에서 딱 들어맞아 성립하진 않지만, 대략적인 서버의 최초 커넥션 풀 크기를 선정하는 기준으로써 사용한다면, 기본적으로 이렇게 세팅해놓고 서버의 성능과 부하에 따라 변경하면 매우 유용할 것입니다.
가장 좋은 방법은 실제로 성능 테스트를 진행해가며 자신의 서버에 맞는 커넥션 풀을 정하는 것이겠죠?
댓글남기기