
[운영체제] 스레드의 이해
서론
이 강의는 유튜브 - 주니온TV의 운영체제 강의를 듣고 정리한 내용을 기록한 게시물입니다.
스레드란?
저번 게시물에서 프로세스에 대해 다루면서, 컨텍스트 스위칭과 프로세스간 통신에 대해서 공부했었다.
프로세스는 순차적으로 CPU를 점유하는데, 이때 하나의 프로세스가 CPU 점유를 마치고 기존에 작업했던 내용을 PCB에 저장하고 다음 처리할 프로세스를 실행하기위해 다음 프로세스의 PCB를 가져오는 과정을 컨텍스트 스위칭이라 한다.
이러한 컨텍스트 스위칭은 비용이 꽤 드는 작업이기 때문에, 같은 프로그램내에서의 작업이 필요하다면 굳이 이러한 비용을 지불할 필요가 없다.
이러한 비효율을 해결하기 위해 사용하는 것이 스레드이다.
스레드의 장점
Responsiveness (응답성)
클라이언트가 서버와 소켓으로 통신할때, 스레드를 통해 멀티스레딩을 사용한다면, 프로세스가 블락킹되어 있을 필요 없이 논블락킹으로 요청을 처리할 수 있기 때문에 큰 파일을 전송하거나 요청이 오래걸리더라도 다른 작업을 할 수 있어 응답이 빠르다.
Resource Sharing (자원 공유)
스레드를 사용하지 않는다면 다른 프로세스를 fork() 해야 하기 때문에 shared memory나 message passing을 통해서 자원을 주고받아야하지만, 스레드의 경우 코드와 데이터 영역을 공유하므로 이러한 프로세스 간 통신이 없이도 자원을 공유하여 사용할 수 있다.
뿐만아니라 컨텍스트 스위칭에 드는 자원또한 절약 가능하다.
Scalability (확장성)
CPU가 멀티 프로세서 구조일 경우에 이점을 적극 활용가능하다. 다중 CPU 구조에서는 각각의 스레드가 프로세스에서 병렬로 수행되기 때문에 병렬성이 증가한다.
자바에서의 스레드
자바에서 스레드를 구현하는 방법은 두가지가 있다.
- Thread 클래스를 상속받아 구현
- Runnable 인터페이스를 Implements 하여 구현
두 경우 모두 public void run() 메소드를 오버라이딩 해주어야 한다.
자바의 경우는 다중 상속이 불가능하므로, 1번의 방식으로 구현하면 다른 상속이 불가능해진다. 따라서 자바에서는 2번의 방식으로 스레드를 구현하는 것을 권장한다.
또, 번외로 익명함수 lambda를 사용하여 클래스를 구현하지 않고 바로 작성하는 방법이 있는데, 이 방법도 사용하긴 하지만 재사용성이 떨어지므로 주로 2번의 방식을 사용한다.
Thread 상속
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
public class Main {
public static void main(String[] args) {
MyThread thread = new MyThread();
thread.start();
System.out.println("Hello, My Child");
}
}
class MyThread extends Thread {
@Override
public void run() {
try {
while (true) {
System.out.println("Hello, Thread!");
Thread.sleep(500);
}
}
catch (InterruptedException e) {
System.out.println("I'm interrupted");
}
}
}
위 코드는 스레드를 상속받아 구현한 방식이다.
여기서 중요한점은 바로 run() 메소드를 오버라이딩 해놓고는 start()를 사용하여 스레드를 동작시켰다는건데, 이 부분은 중요한 부분이므로 뒤에서 설명하도록 하겠다.
Runnable 인터페이스 구현
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
public class Main {
public static void main(String[] args) {
Thread thread = new Thread(new MyThread());
thread.start();
System.out.println("Hello, My Child");
}
}
class MyThread implements Runnable {
@Override
public void run() {
try {
while (true) {
System.out.println("Hello, Thread!");
Thread.sleep(500);
}
} catch (InterruptedException e) {
System.out.println("I'm interrupted");
}
}
}
이번에는 Runnable 인터페이스를 구현하여 스레드를 구현해보았다.
Runnable 방식은 Thread의 객체를 만들어준 뒤, 이 스레드에 해당 Runnable 객체를 생성자 매개변수로 넣어주어야 한다.
Lambda 익명함수를 통한 구현
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
public class Main {
public static void main(String[] args) {
Runnable task = () -> {
try{
while (true) {
System.out.println("Hello Thread!");
Thread.sleep(500);
}
} catch (InterruptedException e) {
System.out.println("I'm interrupted");
}
};
Thread thread = new Thread(task);
thread.start();
System.out.println("Hello, My Child!");
}
}
이번에는 익명함수를 통해 구현해보았다. 이 방법은 클래스를 따로 만들지 않고 바로 스레드를 구현하는데, 재사용성이 떨어지므로 좋은 방법은 아닌 것 같다.
스레드의 동시성
위 프로그램들을 돌리면 특이한 점을 관찰 할 수 있는데, 바로 결과가 매번 같지 않다는 것이다.
분명 main 함수대로라면 Hello, Thread가 먼저 출력되고 Hello My Child가 나와야 하는데, 프로그램을 여러번 돌리다보면 아래와 같은 상황이 생긴다.
1
2
3
Hello, My Child
Hello, Thread!
Hello, Thread!
아까 설명했듯이 스레드는 논블락킹이기 때문에, Thread.start()가 먼저 있지만 해당 함수가 반환을 끝내지 않아도 프로그램은 바로 아래줄을 실행시킨다.
따라서 스레드로 컨텍스트 스위칭이 빨리 일어나면 스레드가 먼저 실행되고, 느릴때에도 반환을 기다리지 않고 바로 다음 명령을 실행하는 것이다.
run()과 start()의 차이
위에서 스레드를 구현함에 있어서 run()을 오버라이딩 해주어 우리가 원하는 작업을 작성하였는데, 멀티스레딩을 사용하고 싶다면 반드시 start()를 사용하여 스레드를 실행시켜야 한다.
그 이유는 둘의 차이가 새로운 호출 스택을 만드는지 아닌지에 있는데, run의 경우는 새로운 호출 스택을 만들지 않기 때문에 사실 상 싱글 스레드로 동작한다.

위 그림을 보면, run() 실행시 별도의 호출 스택이 있는 것이 아니기 때문에 다른 함수와 동일하게 run()이 실행되고, 종료되어 스택에서 pop()된 뒤에 main이 종료된다.
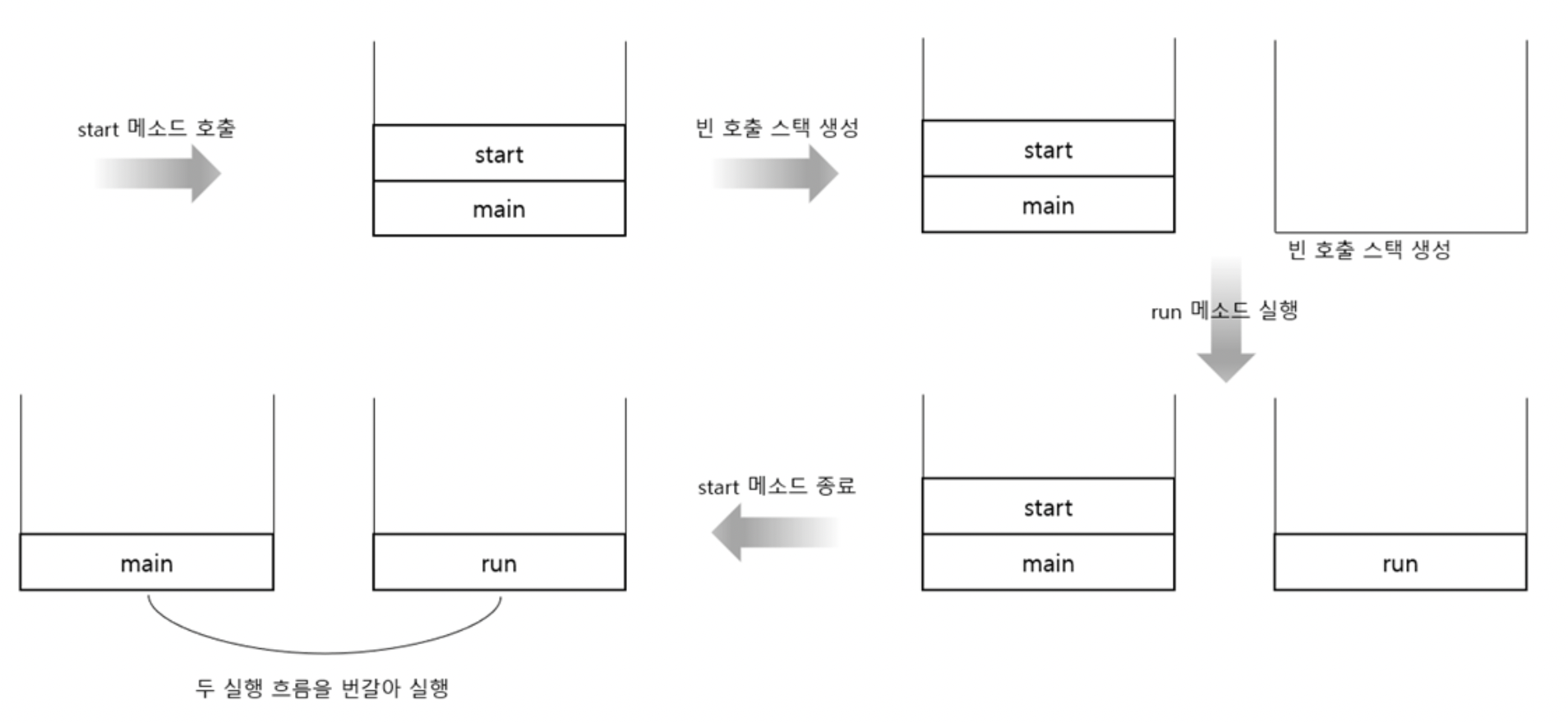
위 그림은 start()로 스레드를 실행시킨 그림이다. start()를 사용하면 start()가 별도의 호출 스택을 만든 뒤, 이곳에서 run()을 실행한다. 따라서 별도의 호출 스택이 생겼기 때문에 run()이 종료되고 main()이 실행되는게 아니라 main과 run이 번갈아 가며 CPU를 점유하는 멀티스레딩이 구현된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public class Main {
public static void main(String[] args) {
Thread thread = new Thread(new MyThread());
thread.run();
for (int i = 0; i < 3; i++) {
System.out.println("Hello, Child!");
}
}
}
class MyThread implements Runnable {
@Override
public void run() {
for (int i = 0; i < 3; i++) {
System.out.println("Hello, Thread!");
}
}
}
위 예제는 start()가 아닌 run()을 사용하여 스레드에서는 Hello, Thread!를 3번, 메인에서는 Hello child!를 3번 출력하게 한 코드이다.
아무리 프로그램을 여러번 실행시켜도 다음과 같은 결과가 나온다.
1
2
3
4
5
6
Hello, Thread!
Hello, Thread!
Hello, Thread!
Hello, Child!
Hello, Child!
Hello, Child!
호출 스택이 생성되지않아, 멀티스레딩이 구현되지 않음을 확인 할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
public class Main {
public static void main(String[] args) {
Thread thread = new Thread(new MyThread());
thread.start();
for (int i = 0; i < 3; i++) {
System.out.println("Hello, Child!");
}
}
}
class MyThread implements Runnable {
@Override
public void run() {
for (int i = 0; i < 3; i++) {
System.out.println("Hello, Thread!");
}
}
}
하지만 위 코드처럼 start()를 사용하면, 호출 스택이 따로 생성되어 동시에 실행되므로 매번 다른 결과를 얻는 것을 확인 할 수 있다.
멀티코어 시스템에서의 주의점
1) Identifying task
어떤 작업에 스레드가 적합한지 알아야한다.
예를들어, 하나의 배열에 있는 숫자들을 모두 더하는 작업에서는 스레드를 사용하여 1-10까지는 첫번째 스레드, 11-20까지는 두번째 스레드가 더해서 최종 합을 구하는등의 방식으로 처리 할 수 있겠지만, 만약 배열을 정렬해야 한다면, 스레드가 완전히 병렬적으로 이를 동시에 처리할 수 없다.
따라서, 해당 작업이 멀티스레딩을 적용할 수 있는 방식인지 고민해보아야한다.
2) Balance
예를들어 20까지 있는 배열을 첫번째 스레드에게는 17개를 더하라고 시키고, 두번째스레드에는 남은 3개를 더하도록 했다면, 하나의 스레드는 일을 더 많이하고 다른 스레드는 놀게된다. 이처럼 스레드가 비슷한 양의 작업을 할 수 있도록 조정해주어야 최대의 효율을 얻을 수 있다.
3) Data splitting
2번과 마찬가지로, 데이터 또한 나누어서 효율적으로 스레드가 데이터를 처리하게 해야한다.
4) Data dependency
서로 의존성을 가지고 있는 데이터를 처리하는 과정에서는, 문제가 일어나지 않도록 의존성에 따른 동기화를 진행해주어야 한다.
5) Testing and debugging
아까의 예제에서 보았듯이, 멀티스레딩 환경에서는 결과값이 항상 다르게 나오는 경우가 존재하기 때문에, 테스트와 디버깅이 싱글 스레딩 환경보다 훨씬 까다롭고 복잡하다. 따라서 이 부분 또한 주의하여 프로그래밍 해야한다.
암달의 법칙
그렇다면, 코어가 무조건 많으면 좋을까?
이러한 것을 계산한 법칙이 있는데, 바로 암달의 법칙(Amdahl’s Law)이다.
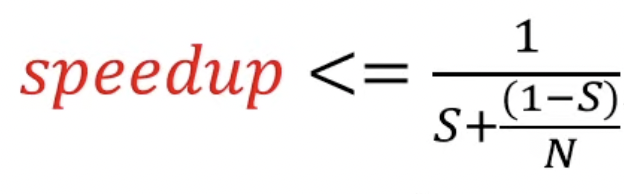
다음과 같은 공식을 따르는데, S는 시스템에서 순차적으로 실행되야하는 부분들의 비율이고, N은 코어의 개수를 뜻한다.
따라서, 만약 S가 0.25이고 N = 2라면 단순하게 생각했을 때는 코어가 2개이므로 2배 빨라져야하지만 어차피 25퍼센트는 병렬적으로 실행하지 못하는 코드이므로 공식에 따라 1.6배만 빨라진다.
코어의 개수를 더 늘려보면,
S = 0.25, N = 4 일때,
speedup은 2.28로 4배가 빨라지는게 아니라 2.28배만큼만 빨라진다.
따라서, 프로그램이 얼마나 병렬적으로 실행될 수 있는지에 따라 코어 개수에 따른 속도 증가가 많이 달라지게 된다.
결론
멀티 스레딩 환경부터는 지금까지 공부했던 내용들과 다른 내용들이 많이 나오는 것 같다.
마치 우리의 세계에서는 당연히 여기던 일들이 양자역학이 지배하는 미시세계로 가면 당연하지 않듯이, 싱글 스레드 환경에서는 당연하던 것들이 멀티스레딩에서부터는 당연하지 않기 때문에 훨씬 복잡해지고, 어려워지는 것 같다.
옛날에는 무어의 법칙에 따라 하드웨어의 성능이 빠르게 증가하면서 멀티 스레딩을 사용하지 않아도 싱글코어 자체 성능 증가로 알아서 프로그램의 성능이 증가했지만, 트랜지스터 집적도가 한계에 다다르면서 더이상 싱글 코어하나의 성능 증가폭이 크게 줄었다.
따라서 하드웨어의 성능을 늘리기위해서 코어자체의 성능을 늘리기보다는 코어를 여러개 늘려가는 방식으로 하드웨어의 성능을 높이고 있는데, 이말은 곧 멀티 스레딩을 사용하지 않으면 하드웨어의 성능을 100퍼센트 사용할 수 없다는 뜻이다.
그렇기 때문에 개발자라면 멀티스레딩이 아무리 어렵고 어려울지라도… 열심히 공부해야만 한다.
댓글남기기